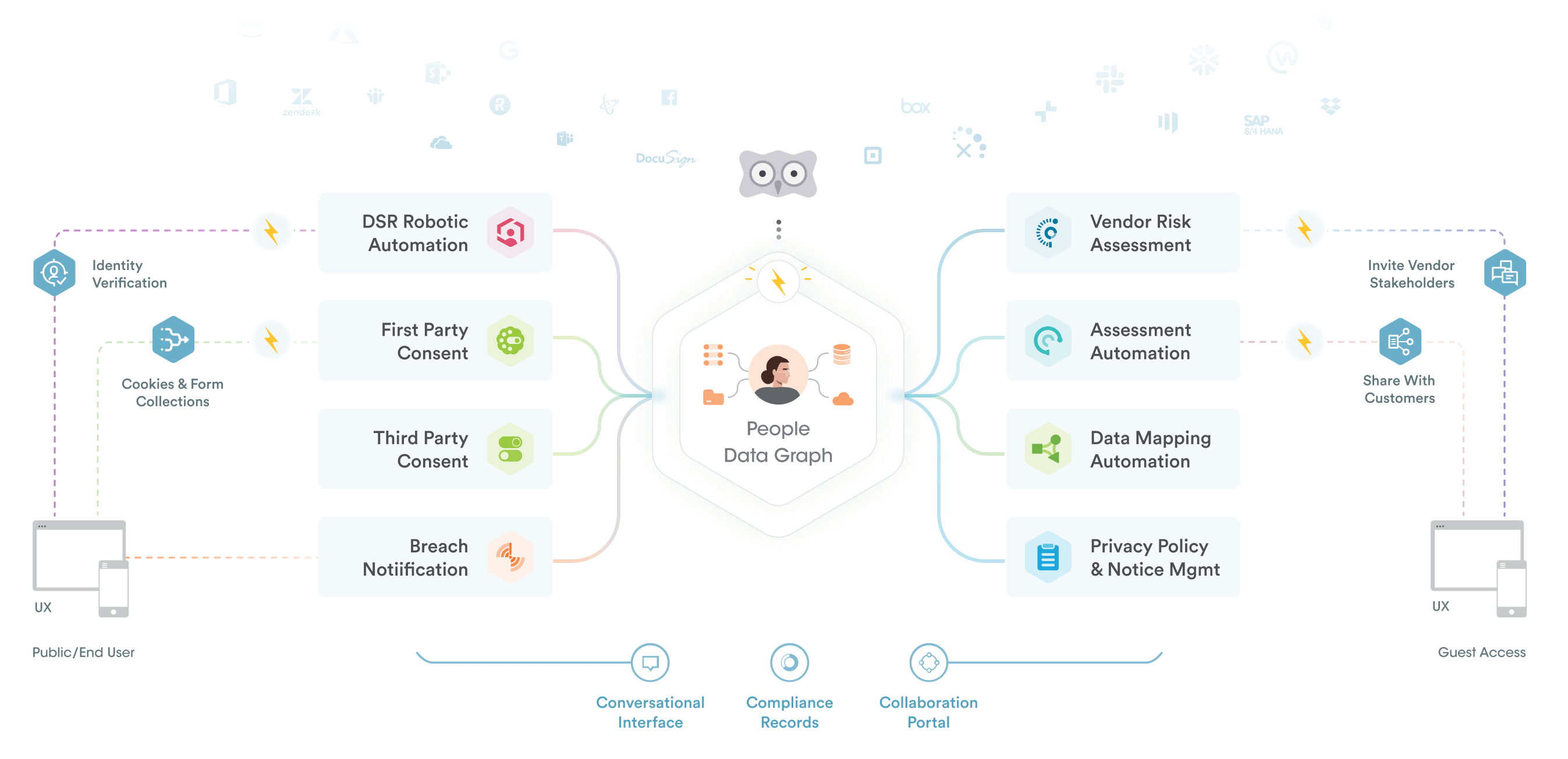
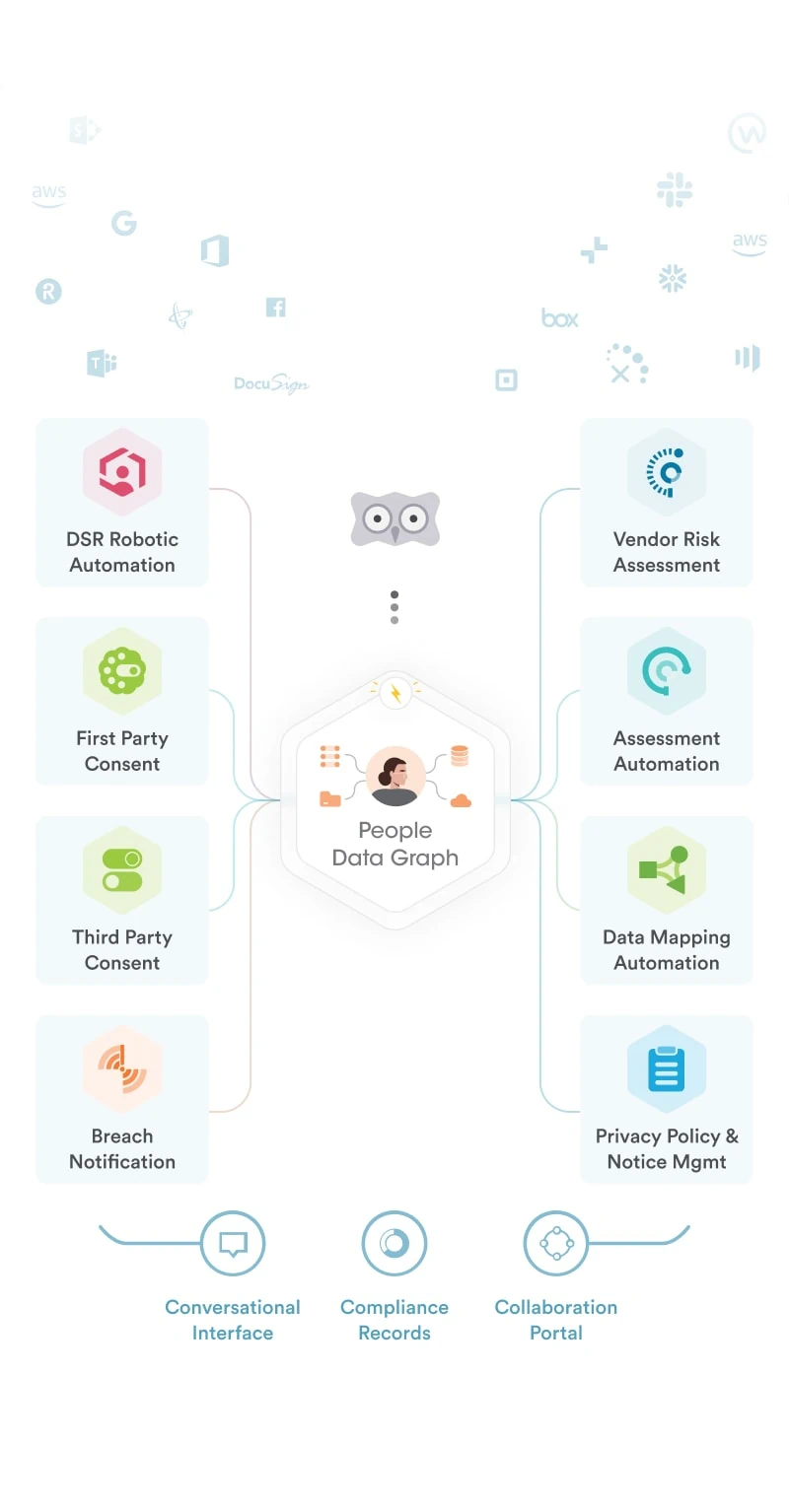
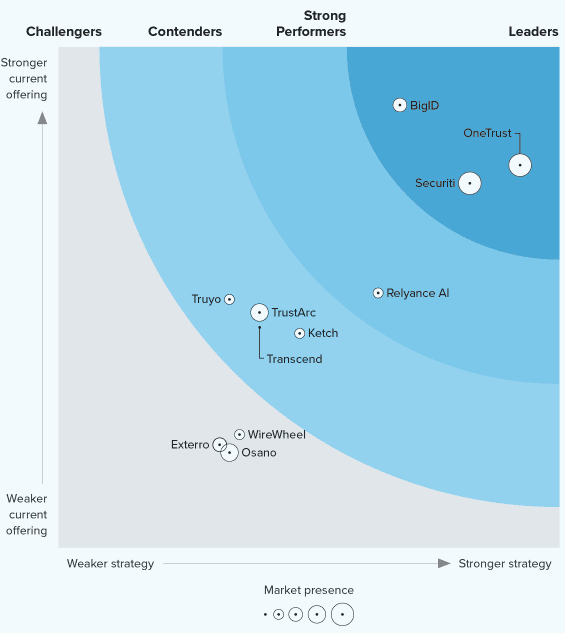

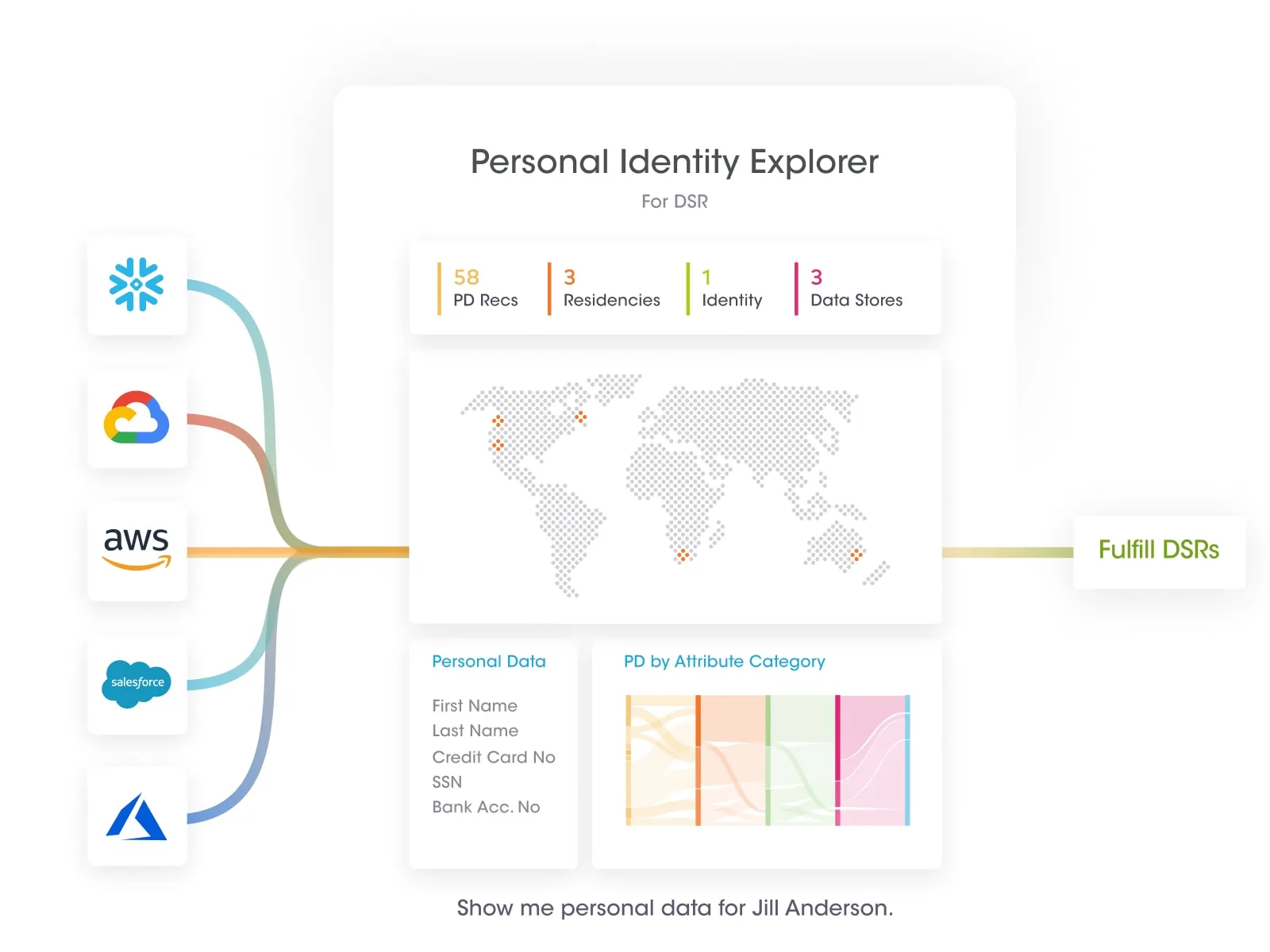
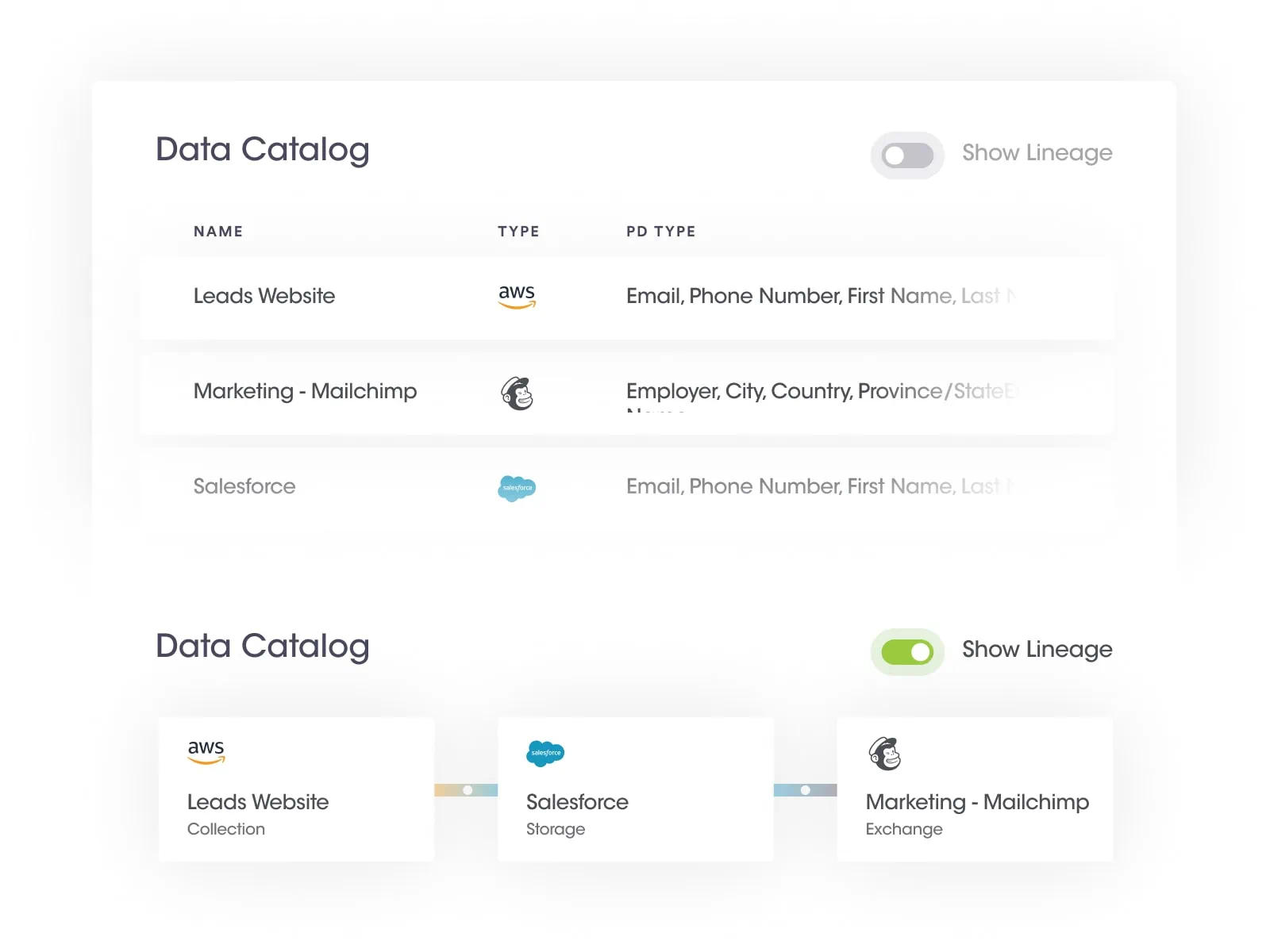
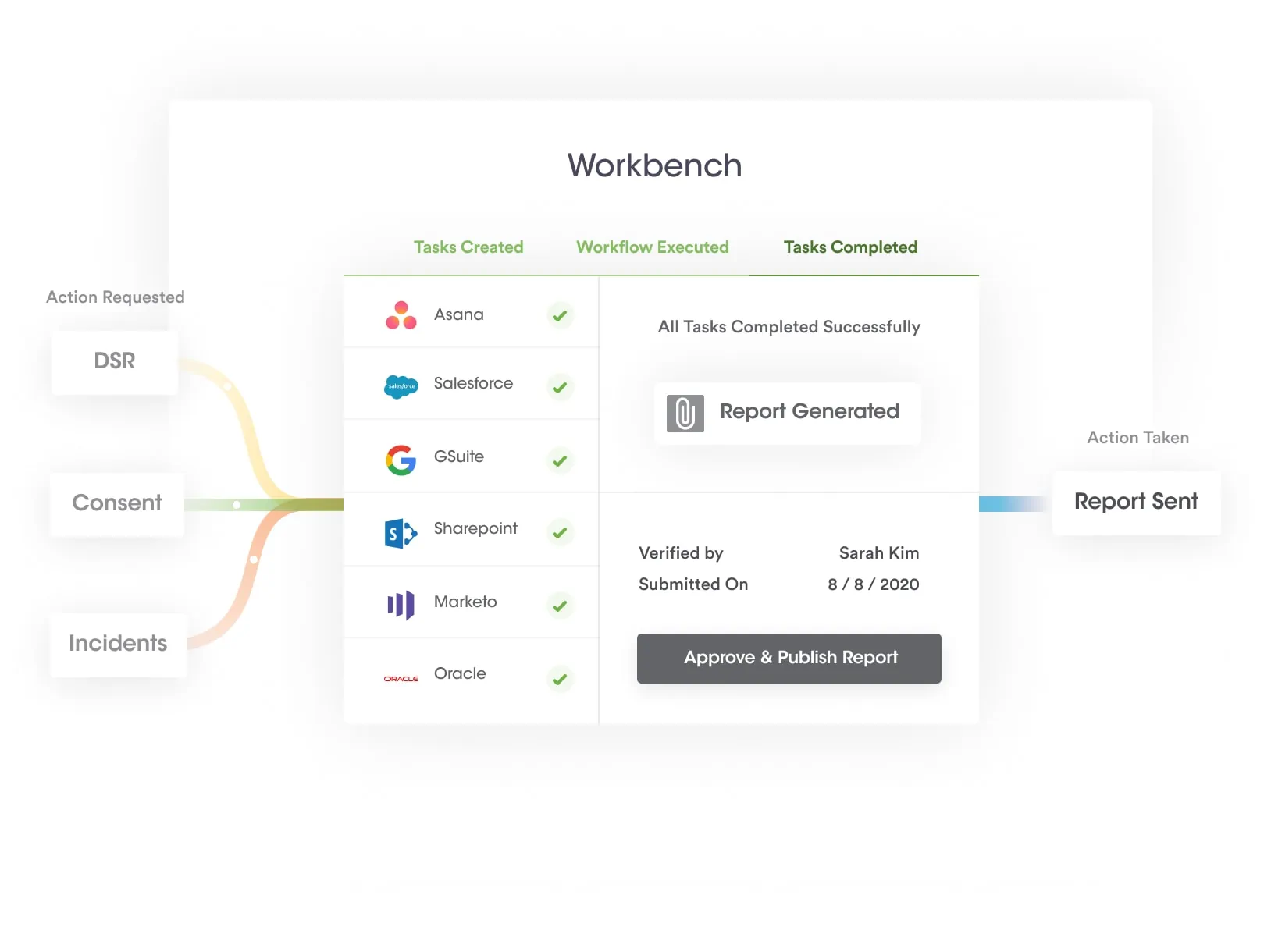
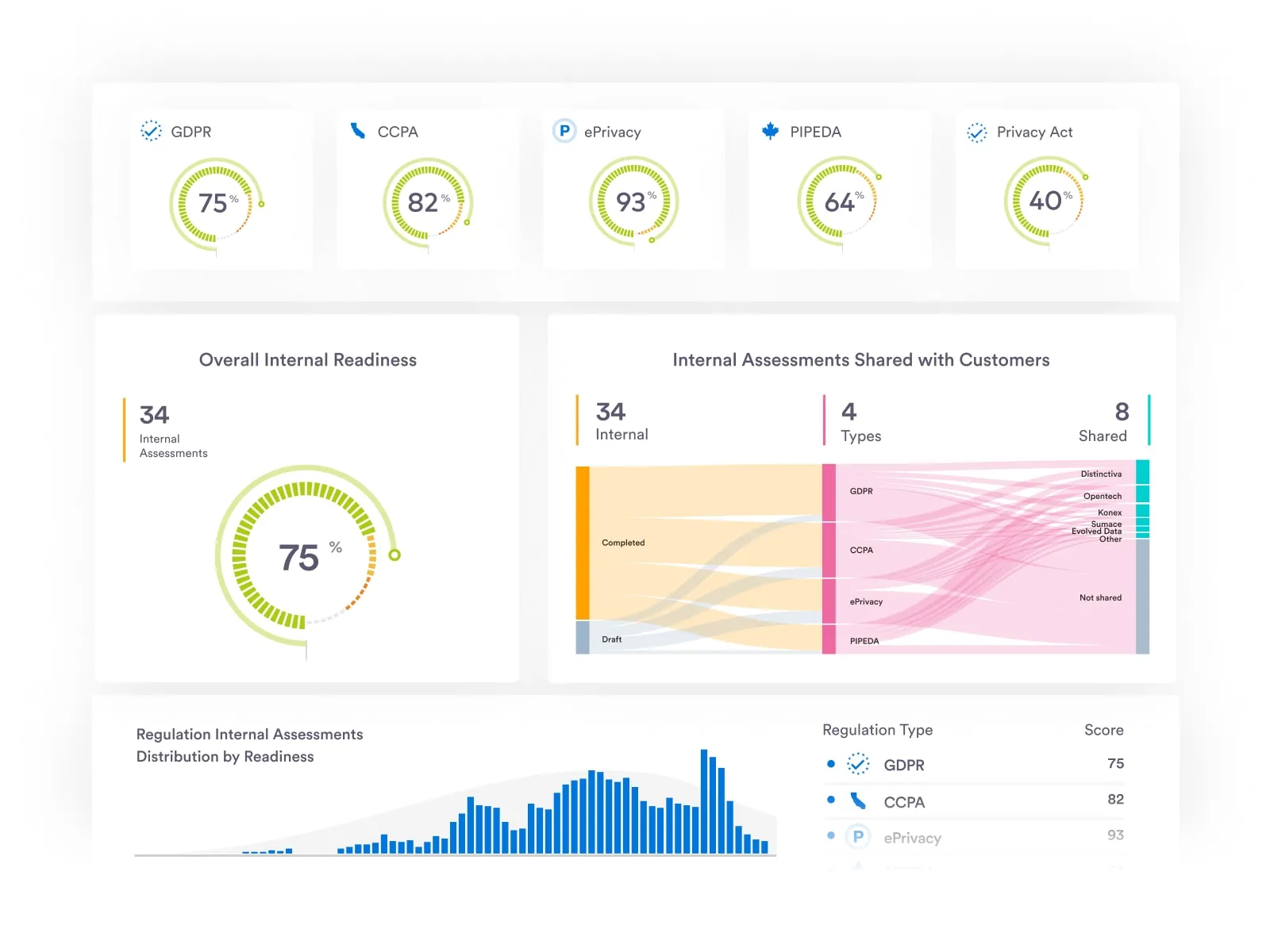
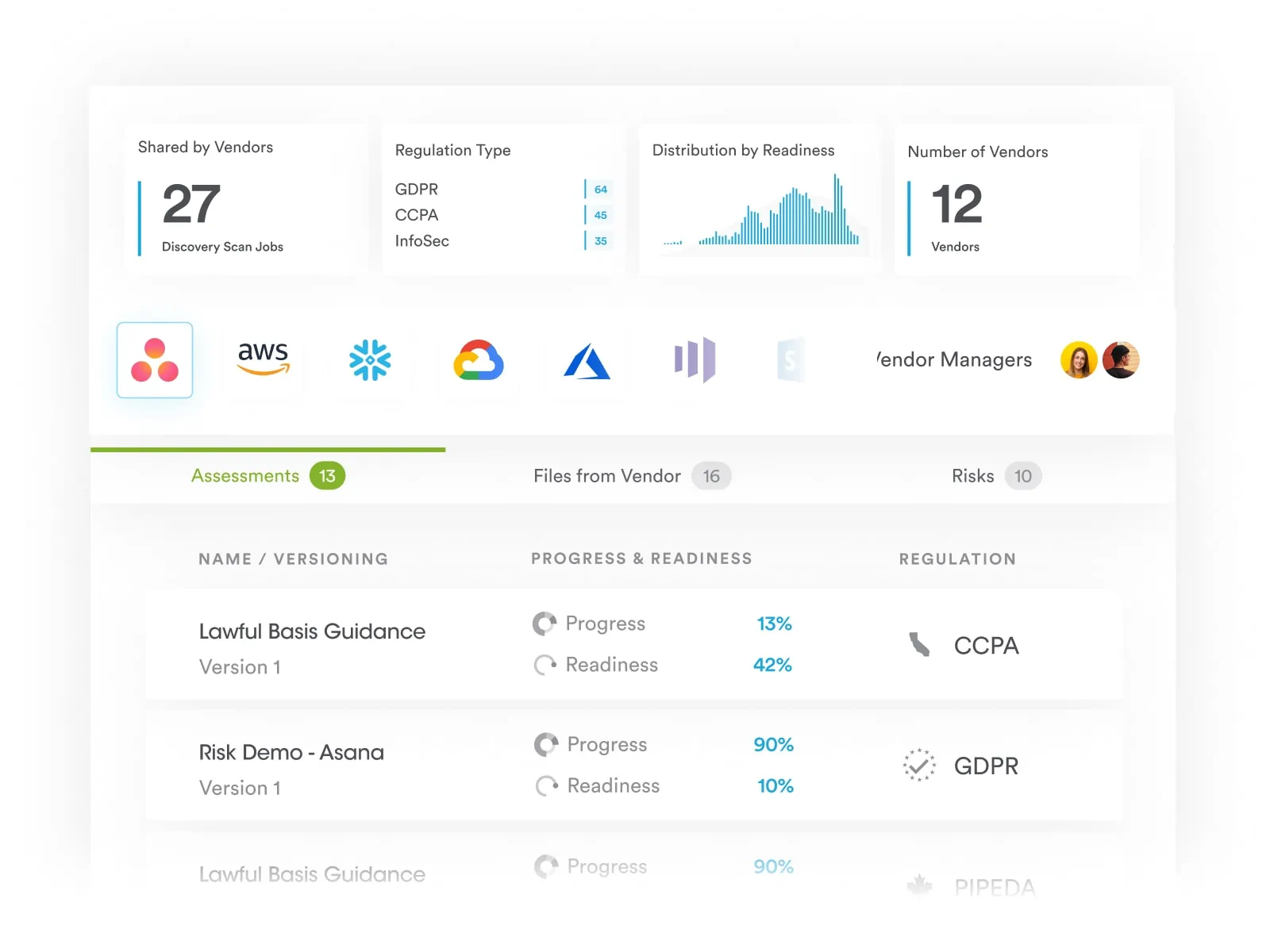
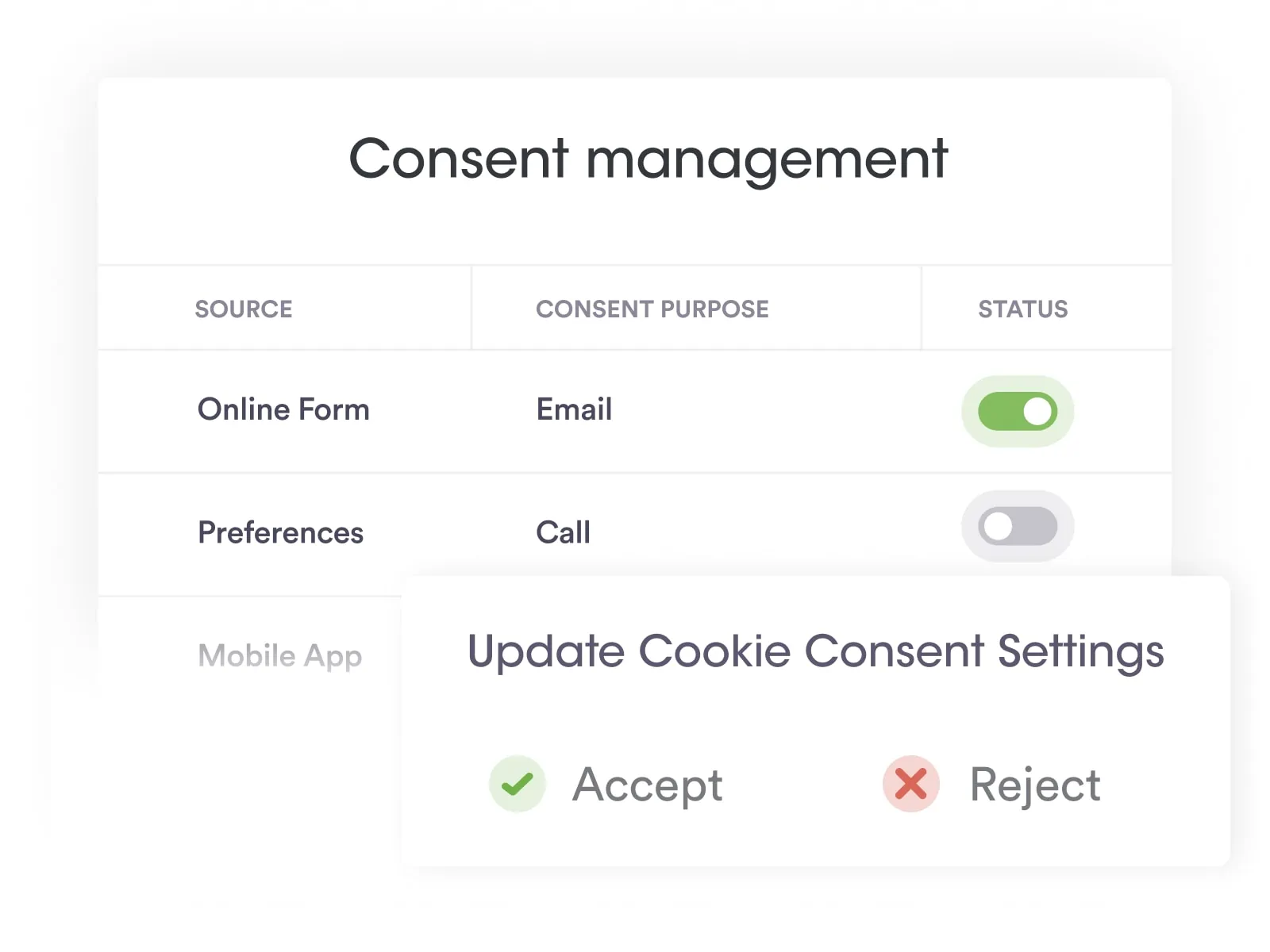
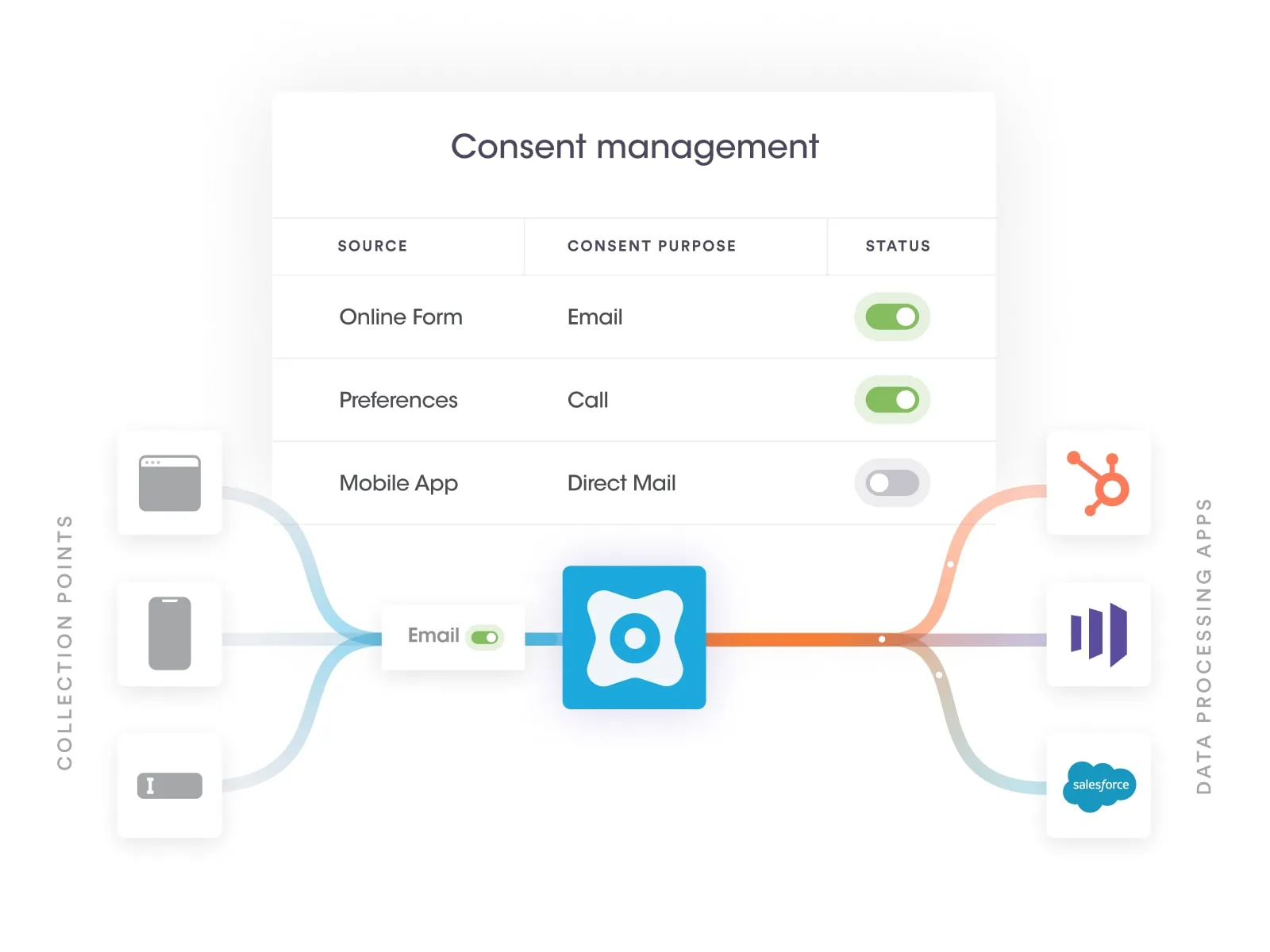
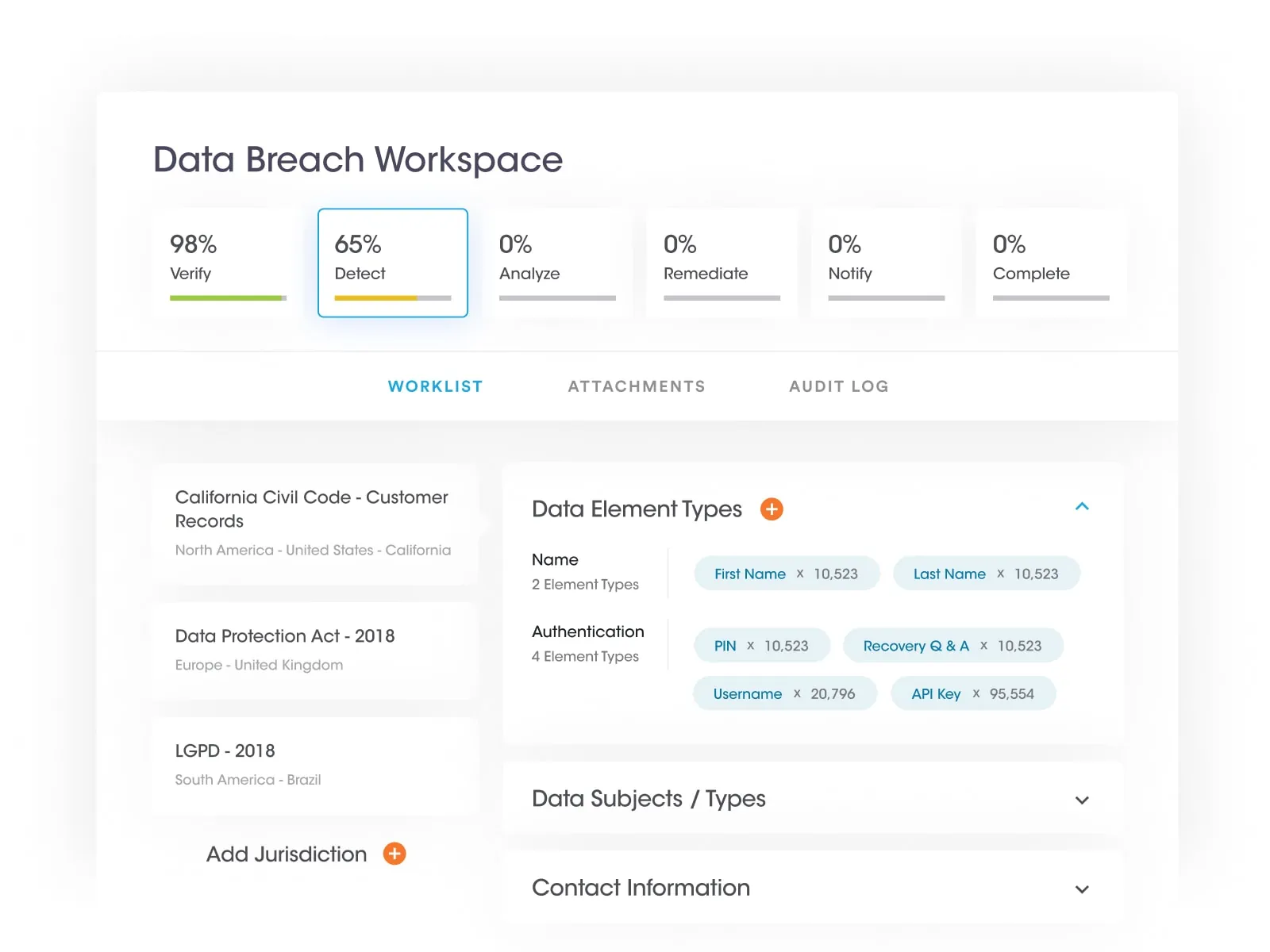
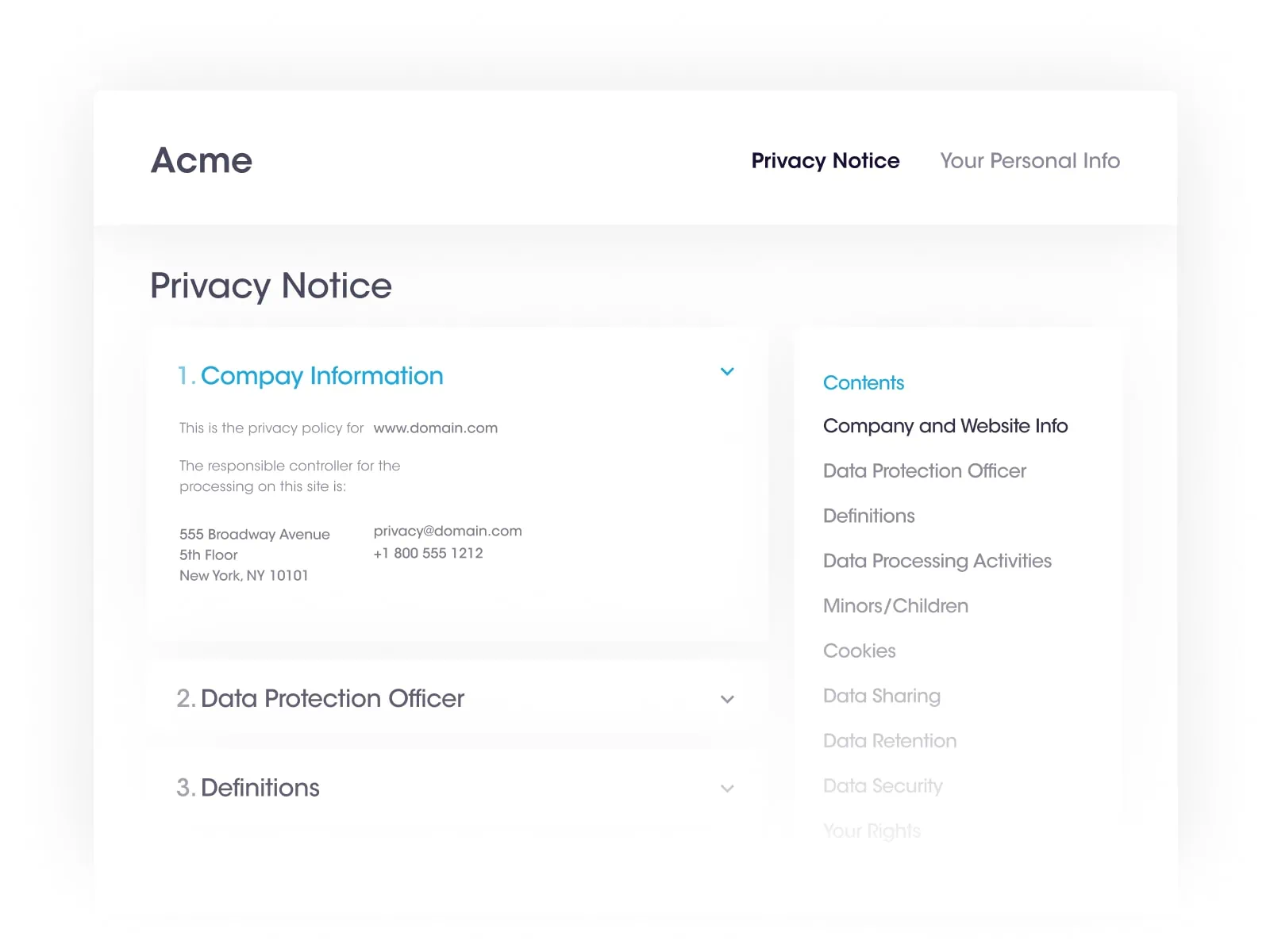
At Securiti, our mission is to enable organizations to safely harness the incredible power of Data & AI.
Copyright © 2024 Securiti · Sitemap · XML Sitemap
Newsletter
Company
Resources
Terms
Get in touch
info@securiti.ai
Securiti, Inc.
300 Santana Row
Suite 450
San Jose, CA 95128




















